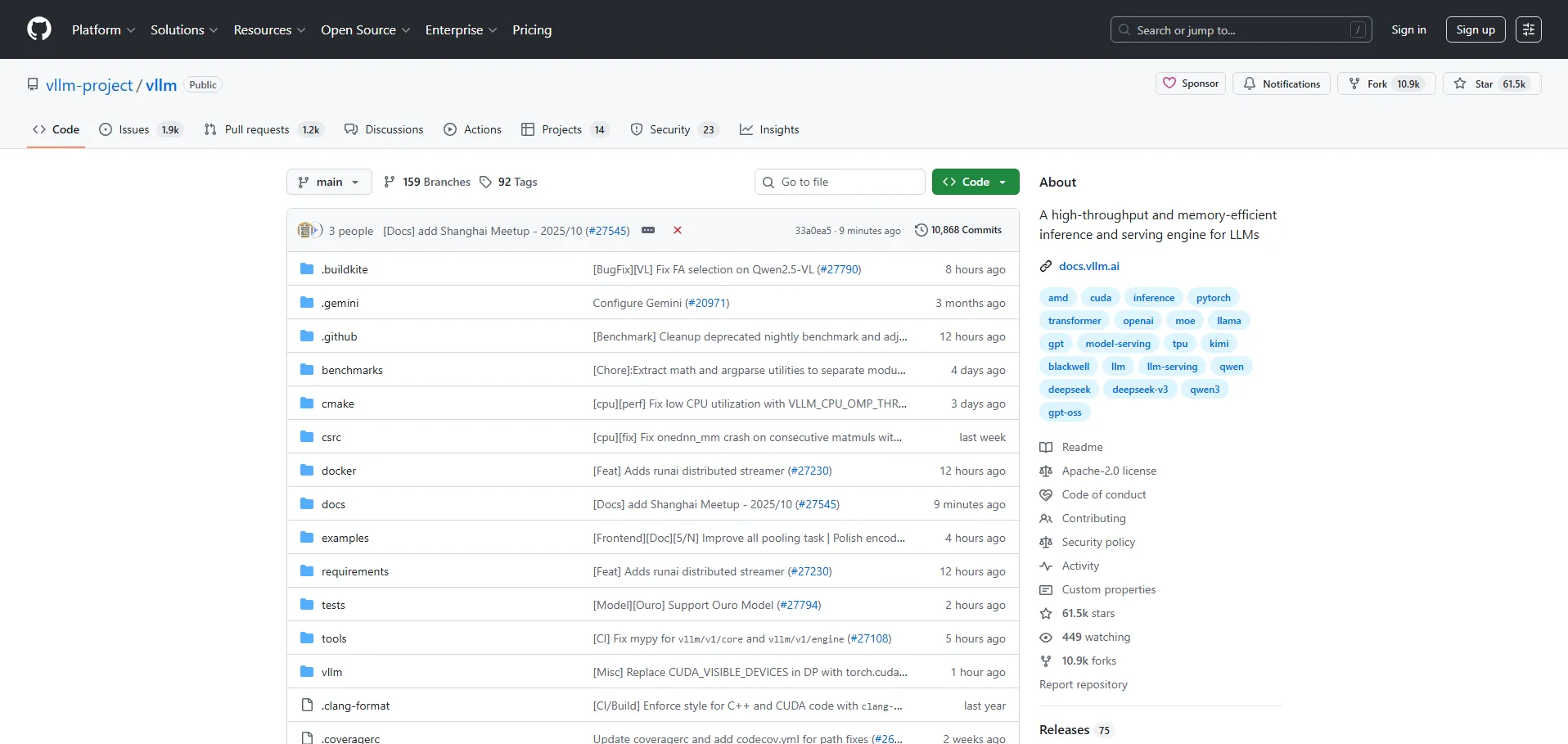
✅ Motor de inferencia de alto rendimiento: maximiza el throughput con latencia reducida.
✅ Gestión eficiente de memoria: ajusta dinámicamente el uso de VRAM para modelos LLM.
✅ Escalabilidad multinodo: distribuye la carga en clusters para un rendimiento constante.
✅ Soporte multiplataforma: compatible con GPU, CPU y servicios en la nube.
✅ API programática: integra fácilmente la inferencia en pipelines de IA existentes.
💡 Despliegue en la nube: sirve modelos LLM de alto tráfico con baja latencia en AWS, GCP o Azure.
💡 ☁️ Infraestructura on-premise: gestiona inferencia en centros de datos internos con control total de recursos.
💡 ️ Integración en pipelines CI/CD: automatiza pruebas de rendimiento y escalado continuo de modelos.
💡 Procesamiento de consultas en tiempo real: alimenta chatbots y asistentes virtuales con respuestas instantáneas.
💡 Investigación y desarrollo: experimenta con nuevos arquitecturas de LLM sin preocuparte por el consumo de memoria.